How to Use NDepend’s Trend Charts
Editorial note: I originally wrote this post for the NDepend blog. You can check out the original here, at their site. While you’re there, download NDepend and give the trend chart functionality a try.
Imagine a scene for a moment. A year earlier, a corporate VP spun up a major software project for his organization. He brought a slew of his organization’s software developers into the project. But he also needed to add more staff in the form of contractors.
This strained the budget, so he cut a few corners in terms of team member experience. The VP reasoned that he could make up for this with strategic use of experienced architects up front. Those architects would prototype good patterns and make it so the less seasoned contractors could just kind of paint by numbers. The architects spent a few months doing just that and handed the work off to the contractors.

Fast forward to the present. Now a consultant sits in a nice office, explaining to a beleaguered VP how they got so far behind schedule. I can picture this scene quite easily because organizations hire me to be this consultant. I live this scene over and over again.
NDepend Trend Charts
Concepts like technical debt help quite a bit. I also enlist various other metaphors to help them understand the issues that they face. But nothing hits home like a visual. I’ve described this before. Generate an actual dependency map of their codebase and show it next to the ones the architects created in Visio, and you invariably see a disconnect.
Today, I’d like to take a look at another visual feature of NDepend: trend charts. These allow you to see a graph-style representation of your codebase’s properties as a function of time. And you can customize them a great deal.
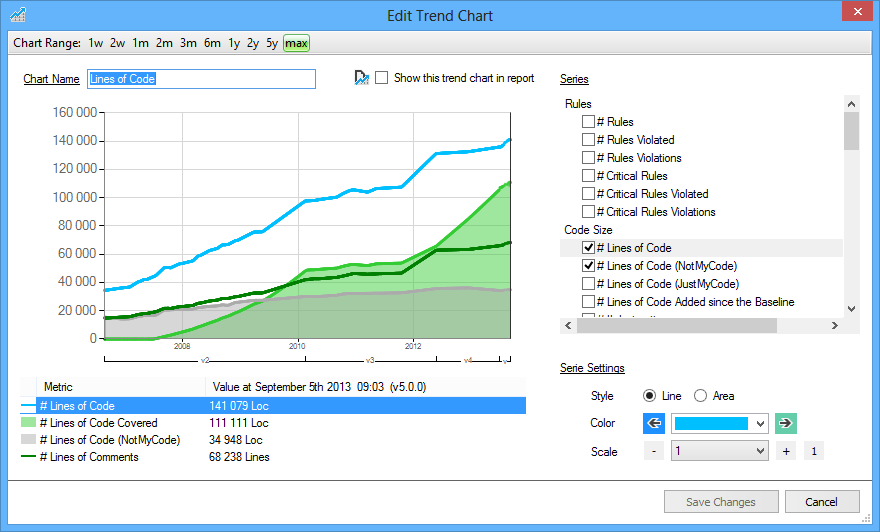
In the scene I painted for you a moment ago, the VP—and the people in his program—feel pain for a specific reason. They go far too long without reconciling the plan with reality. I come along a year in and generate a diagram that they should have looked at all along.
Trend charts, by design, help combat that problem. They allow you to get a feel for strategic properties of a codebase. But they allow you to see how that property varies with time. You can take advantage of that in some powerful ways.





